How Do the Top AI Voice Generators Compare?
In the symphony of technological advancements, AI voice generators have emerged as the virtuosos of vocal synthesis, transforming text into speech with an unprecedented level of human-like quality. But with a chorus of options available, each claiming to be the best, how do you discern the maestro from the mere mimic? The search for the best AI voice generator is not just about finding a tool that can speak; it's about discovering a voice that resonates with clarity, emotion, and authenticity. In this blog post, we will explore the leading AI voice generators that are setting the tone for the future of synthesized speech.
From the sophisticated algorithms of DeepBrain AI's AI Studios to the widely recognized Google Text-to-Speech, each AI voice generator brings a unique timbre to the table. Amazon Polly's lifelike voices and IBM Watson's Text to Speech's versatility are also key players in the quest for the perfect digital orator. But what makes an AI voice generator truly stand out? We will delve into the evaluation criteria that separate the best from the rest, providing you with a harmonized comparative analysis of the leading AI voice generators. Whether you're creating content for videos, podcasts, or looking to enhance user experience with voice-enabled applications, this post will guide you to the AI voice that hits the right note for your needs.
1. DeepBrain AI's AI Studios
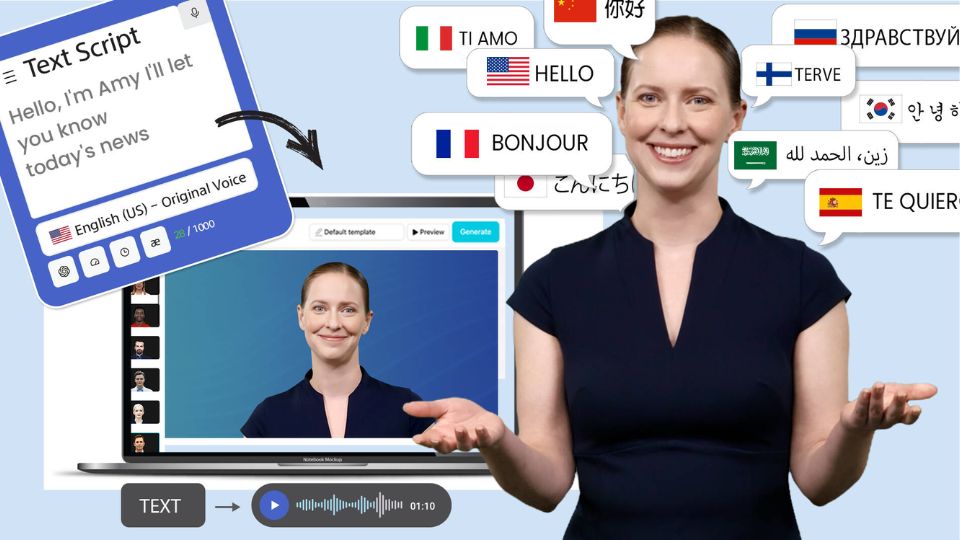
DeepBrain AI's AI Studios is at the forefront of AI voice generation technology, offering users the ability to create professional-quality videos and voice files directly from their browsers. With its advanced features and user-friendly platform, AI Studios is shaping up to be an indispensable tool in the realm of digital content creation.
Key Features:
- Realistic Voice Synthesis: At the heart of AI Studios lies its state-of-the-art deep learning algorithms. These algorithms are fine-tuned to produce voice outputs that closely mimic human speech, capturing the subtle nuances that make conversations sound natural and engaging. The result is a high-quality voice generation that can elevate any content, whether it's for educational purposes, marketing campaigns, or entertainment.
- Multilingual Support & Diversity: AI Studios boasts support for over 80 languages, making it an ideal solution for creators looking to reach a global audience. With a vast library of over 100 voices, each featuring unique accents and tones, users can select the perfect voice to resonate with their target demographic, ensuring that their message is not only heard but also felt.
- Customizable Speech & Emotion: Flexibility is key in content creation, and AI Studios delivers by allowing users to tailor speech patterns, tones, and emotions. Whether the goal is to inspire, educate, or sell, the platform provides the tools necessary to create a voice that aligns with the intended impact of the content.
- Seamless Integration: AI Studios is designed to integrate smoothly with a variety of software and applications. This interoperability ensures that incorporating AI-generated voice into existing workflows is as straightforward as possible, streamlining the content creation process.
Pros:
- Natural Listening Experience: The lifelike voice synthesis of AI Studios provides listeners with a natural and comfortable auditory experience, crucial for maintaining engagement and conveying authenticity.
- Tone & Emotion Customization: The platform's ability to customize the generated voice to match specific tones and emotions allows for a highly personalized end product, perfect for creating a connection with the audience.
- Versatile Applications: AI Studios is adept at producing content across various domains, including interactive educational materials, compelling marketing videos, and dynamic storytelling.
Cons:
- User Learning Curve: The sophistication of AI Studios may present a learning curve for newcomers. However, the platform is designed with a user-friendly interface to ease the transition and support users in unlocking the full potential of AI voice generation.
- Cost for Some Users: While the advanced features of AI Studios are a significant draw, pricing may be a factor for smaller entities or individual users. It's important to weigh the investment against the potential return in terms of time saved and content quality.
Step-by-Step Guide to Creating Videos with AI Studios
AI Studios by DeepBrain AI offers a streamlined, user-friendly approach to video production. Here's a step-by-step breakdown of how to create compelling videos using this innovative platform:
| Step | Process | Description |
|---|---|---|
| Step 1 | Template Selection or Custom Creation | Choose from a range of templates or start from scratch with an AI avatar and voice that align with your brand and message. |
| Step 2 | Intuitive Editing Experience | Utilize an editor that combines ease of use with comprehensive customization options to fine-tune your video. |
| Step 3 | Diverse Avatar and Language Options | Select from over 100 stock avatars and generate voices in more than 80 languages for global audience reach. |
| Step 4 | Realistic Lip-Sync and Expressions | Benefit from advanced lip-sync technology and realistic expressions to enhance the authenticity of your AI-generated video content. |
Step 1: Template Selection or Custom Creation
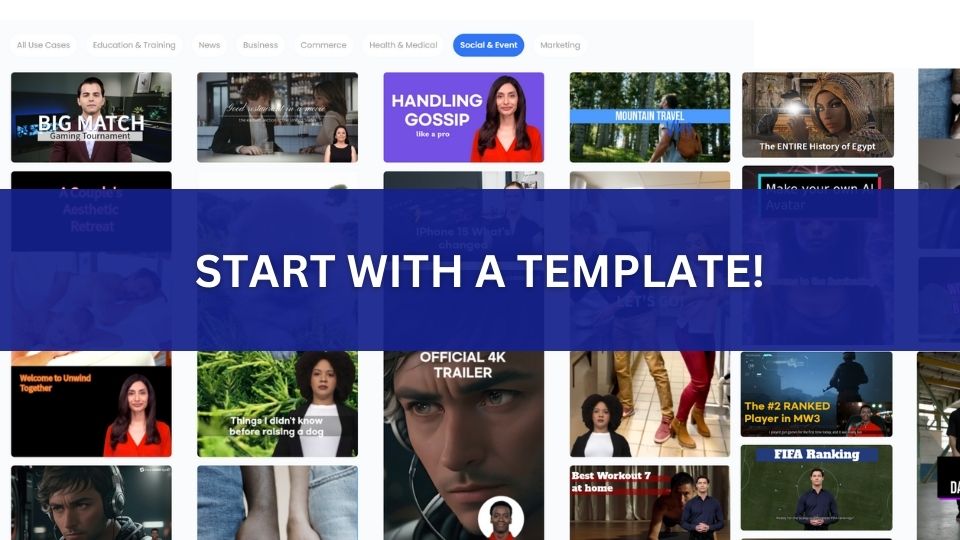
Upon accessing AI Studios, you're presented with a variety of professionally crafted templates, each designed for different video types and purposes. These templates serve as an excellent starting point for projects in marketing, education, entertainment, and more. For a more personalized touch, you can start from scratch by selecting an AI avatar that best represents your brand or message. Pair this avatar with a voice that truly speaks to your audience, ensuring your content has the desired impact.
Step 2: Intuitive Editing Experience
AI Studios features an editor that balances ease of use with a rich set of customization options. This makes it suitable for both novices and experienced users alike. The straightforward interface allows beginners to navigate the video creation process with ease, while the depth of customization will satisfy the needs of professional content creators. Users can meticulously edit their videos, making sure the final product is in complete harmony with their original vision.
Step 3: Diverse Avatar and Language Options
The platform boasts an extensive library of over 100 stock avatars, offering a vast array of characters to bring your message to life. These avatars are designed to reflect a high degree of realism, capturing the subtleties of human expression and making every video production feel unique and engaging. Additionally, AI Studios' capability to generate voices in more than 80 languages demonstrates its commitment to global accessibility, allowing creators to reach and resonate with international audiences without barriers.
Step 4: Realistic Lip-Sync and Expressions
One of the most remarkable features of AI Studios is its AI avatar lip-sync technology. This advanced feature ensures that the avatars' lip movements are in perfect sync with the AI-generated voice, significantly enhancing the authenticity of the video. The combination of precise lip-syncing with natural facial expressions, accents, and intonations provides a level of realism that is comparable to live-action performances, setting a new standard for AI-generated video content.
By following these straightforward steps, users can harness the power of AI Studios to create high-quality, engaging videos that are both realistic and captivating. DeepBrain AI's platform is changing the landscape of video production, making it more accessible and efficient for creators worldwide.
Table of Advantages: AI Studios for Video Production
AI Studios provides a range of benefits that streamline the video production process. Below is a table that outlines the key advantages of using this AI-powered platform:
| Advantage | Impact |
|---|---|
| Efficiency | Eliminates the need for traditional video production equipment and personnel, allowing for the creation of polished videos quickly and with fewer resources. |
| Scalability | Designed to support the production of video content at scale, making it ideal for businesses and creators who require a consistent output of high-volume content. |
| Global Appeal | Offers voice generation in a wide array of languages and accents, breaking down language barriers and enabling content to be tailored for a global audience. |
| Cost-Effectiveness | Saves significant costs associated with traditional video production, such as equipment, studio hire, and actors, thereby democratizing access to professional-quality video content. |
2. Google Text-to-Speech
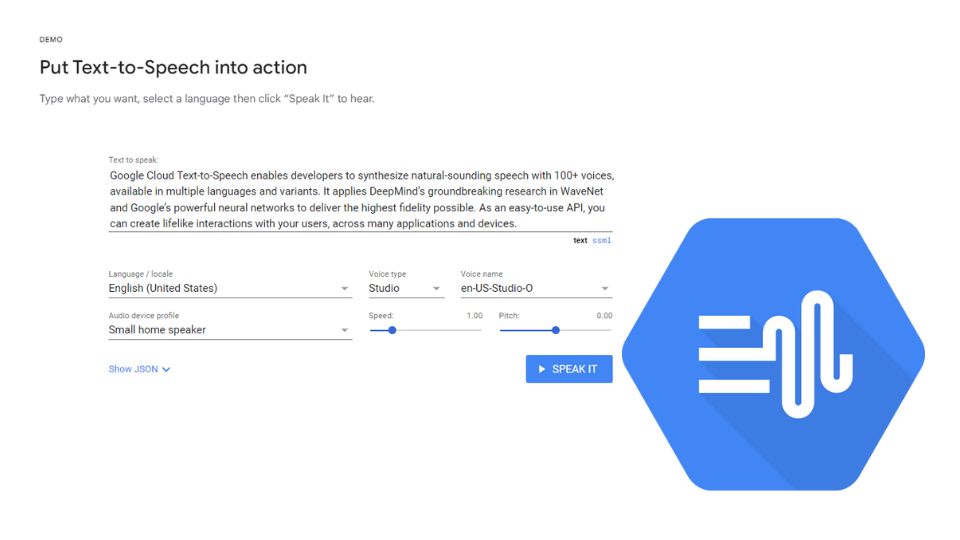
Google Text-to-Speech API is a powerful voice generator that utilizes Google's neural network models to convert text into lifelike spoken audio. This API is part of Google Cloud's suite of machine learning tools and stands as a popular choice for developers looking to integrate speech synthesis into their applications..
Key Features:
- WaveNet Technology: At the core of Google's Text-to-Speech API is WaveNet, a deep generative model of raw audio waveforms developed by DeepMind. WaveNet technology allows for the production of richer, more natural-sounding voices by capturing the nuances of human speech, including pitch, pace, and intonation.
- Extensive Language Coverage: Google's API excels in its support for a multitude of languages and dialects, making it a versatile tool for global applications. Whether you need to generate speech in English, Spanish, Mandarin, or any of the other supported languages, Google Text-to-Speech can accommodate your needs.
- Custom Voice: One of the more advanced features of Google Text-to-Speech is the ability to create and train a custom voice model. This is particularly useful for brands or products that want to maintain a unique and consistent voice across their services.
Pros:
- High-Quality Voice Synthesis: Google's neural networks ensure that the synthesized speech is not only high-quality but also remarkably human-like. This is crucial for applications where user experience depends on the naturalness of the voice, such as virtual assistants, audiobooks, or customer service bots.
- Broad Language Support: The API's extensive language and dialect support is ideal for companies with an international user base. It enables the creation of content that is accessible and understandable to users worldwide, which is essential for products and services aiming for global reach.
- Seamless Integration: For those already utilizing Google Cloud services, integrating the Text-to-Speech API is a smooth process. This integration allows for a cohesive development environment and the ability to leverage other Google Cloud features alongside speech synthesis.
Cons:
- Cost Implications for High-Volume Use: While Google Text-to-Speech offers a pay-as-you-go pricing model, costs can accumulate with increased usage. For applications that require large volumes of speech generation, this could become a significant expense.
- Custom Voice Development: Although having a custom voice can be a major asset, the process of creating one involves additional time and resources. Training a custom model requires a dataset of high-quality voice recordings, which may not be feasible for all projects or smaller organizations.
3. Amazon Polly
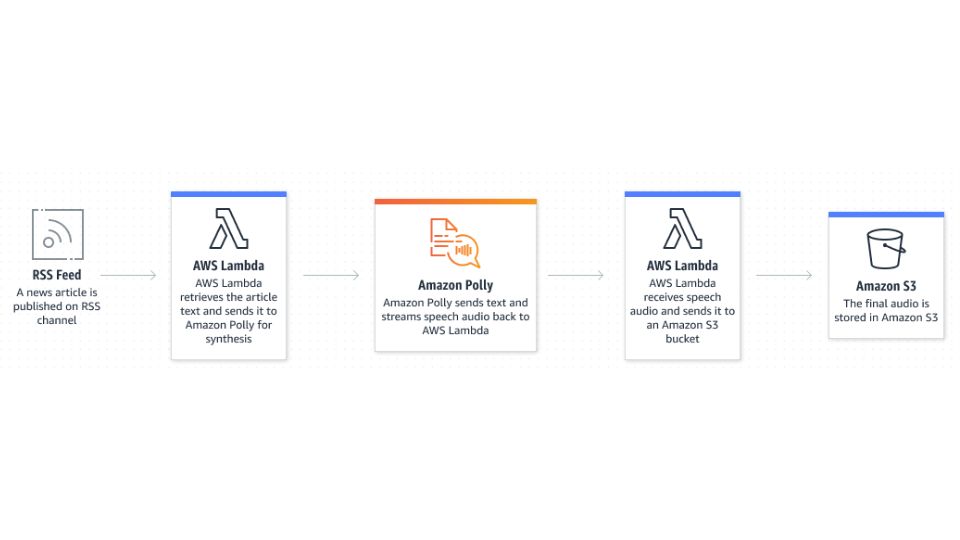
Amazon Polly is a cloud service that converts text into realistic speech, enabling developers to add a voice interface to their applications and create a new breed of speech-enabled products. As a part of the Amazon Web Services (AWS) suite, Polly leverages deep learning technologies to synthesize natural-sounding human speech.
Key Features:
- Lifelike Voices: Amazon Polly's extensive library includes a wide range of high-quality male and female voices across different languages, ensuring that the output closely resembles human speech. The voices vary in accent and style, providing options to match the specific needs of any application.
- Speech Marks: With support for SSML tags, Amazon Polly allows developers to fine-tune the speech output, including aspects like pronunciation, volume, pitch, speech rate, and pauses, giving them control over how the text is expressed verbally.
- Real-Time Streaming: Polly provides the capability to stream synthesized speech in real-time, which is ideal for interactive applications such as virtual assistants, online games, or real-time translations.
Pros:
- Expressive Synthesis: Amazon Polly isn't just about reading text out loud; it's about conveying emotions and expressions, making the interaction more engaging for the end-user. This is particularly beneficial for creating content like audiobooks or customer service chatbots that require a certain level of expressiveness.
- AWS Integration: For those already in the AWS ecosystem, integrating Polly with other AWS services is seamless. This integration can lead to more robust applications, as Polly can be combined with services like Amazon Lex for natural language understanding or AWS Lambda for serverless computing.
- Flexible Pricing: The pay-as-you-go pricing model of Amazon Polly allows for scalability and flexibility. You pay only for the number of characters you convert to speech, making it cost-effective for both small-scale projects and larger enterprises.
Cons:
- Additional Costs: While the pay-as-you-go model is advantageous, costs can add up with extensive use. Streaming or storing large volumes of generated speech may lead to additional expenses, which should be factored into the budget.
- Voice Selection: Although Amazon Polly offers a multitude of voices, some users may find the selection less diverse when compared to other text-to-speech services. This could be a limitation for projects requiring very specific voice types or regional accents.
4. IBM Watson Text to Speech
IBM Watson Text to Speech is part of IBM's robust suite of AI services, designed to transform written text into authentic and natural-sounding speech. Leveraging IBM's artificial intelligence expertise, this voice generator is tailored for a variety of applications, from customer service interfaces to interactive voice response systems.
Key Features:
- Expressive Synthesis: IBM Watson Text to Speech doesn't just read text; it brings narratives to life with emotional depth and variety. The service offers a selection of voices that can convey different emotional tones, such as joy, sadness, or excitement, enhancing the listener's experience.
- Customization: Understanding the importance of brand identity, IBM Watson allows for extensive customization of voice attributes. Users can fine-tune the voice to reflect their brand's personality, creating a unique auditory presence that stands out in the market.
- SSML Support: The service supports Speech Synthesis Markup Language (SSML), which provides detailed control over aspects of speech such as pronunciation, pitch, and speed. This feature is particularly useful for content that requires precise vocal nuances, like educational materials or storytelling.
Pros:
- Diverse Voices and Customization: IBM Watson's array of voices and the ability to customize them provide flexibility for developers to match the voice with the application's context and purpose. This is crucial for creating a seamless and engaging user experience.
- Advanced Voice Synthesis: The technology behind IBM Watson's Text to Speech is rooted in high-quality voice synthesis. This ensures that the spoken output is not only clear but also closely resembles natural human speech, which is essential for maintaining user engagement and trust.
- Seamless Integration: For those who are already utilizing IBM Watson's suite of services, integrating the Text to Speech API is straightforward. This allows for the creation of comprehensive solutions that can leverage other IBM AI capabilities, such as language translation or conversation services.
Cons:
- Cost Considerations for Volume: While IBM Watson Text to Speech offers a robust set of features, the pricing structure may become costly for applications with high-volume text conversion needs. This is an important consideration for businesses that require extensive use of the service.
- Platform Familiarity: New users who are not acquainted with IBM's platform may find the interface less intuitive compared to other text-to-speech services. This could lead to a steeper learning curve and potentially longer development times for those starting fresh with IBM Watson.
Evaluation Criteria for AI Voice Generators: A Tabular Overview
Choosing the right AI voice generator is crucial, and our evaluation criteria are tailored to help you make an informed decision. Here's a table summarizing the key factors to consider:
| Criteria | Description |
|---|---|
| Functionality | Assesses the range of features such as language and accent diversity, emotional tone settings, voice customization, and the overall quality of voice synthesis. |
| Ease of Use | Evaluates how intuitive and accessible the platform is for users of varying expertise, including the availability of learning resources and the simplicity of the voice generation process. |
| Cost-Effectiveness | Examines the pricing structure, looking for competitive rates that align with the features offered, and assesses the overall value for money. |
| Customer Support | Rates the level of assistance provided, including the availability and responsiveness of support channels, as well as self-service resources like FAQs and knowledge bases. |
Comparative Analysis: Leading AI Voice Generators
When selecting an AI voice generator, it's essential to compare the top contenders in the market. Below is a comprehensive table that contrasts the features, pros, and cons of DeepBrain AI's AI Studios, Google Text-to-Speech, Amazon Polly, and IBM Watson Text to Speech.
| Feature/Service | Deepbrain AI's AI Studios | Google Text-to-Speech | Amazon Polly | IBM Watson Text to Speech |
|---|---|---|---|---|
| Voice Synthesis Quality | Realistic voices using deep learning algorithms | High-quality voices with WaveNet technology | Lifelike male and female voices | Natural-sounding voices with emotional tones |
| Language Support | Over 80 languages | Extensive range of languages and dialects | Wide language coverage | Multiple languages and voices |
| Integration | Seamless integration with software and applications | Smooth integration with Google Cloud services | Easy integration with AWS services | Integration with IBM Watson services |
| User-Friendly Platform | Yes, designed for ease of use | Depends on user familiarity with Google Cloud | Yes, especially for those in the AWS ecosystem | May have a learning curve for new users |
| Pricing Model | May be costly for some users | Pay-as-you-go, can be expensive for high-volume use | Pay-as-you-go, additional costs for streaming/storage | May be less competitive for high-volume users |
| Unique Advantages | Realistic lip-sync and expressions; vast avatar selection | Custom voice development; broad language support | Expressive synthesis; real-time streaming | Expressive synthesis; deep customization options |
| Potential Drawbacks | Learning curve for new users; pricing for smaller entities | Cost for high-volume usage; custom voice development complexity | Additional costs for heavy usage; limited voice selection for some users | Higher costs for volume; less intuitive platform for newcomers |
How to Choose the Right AI Voice Generator?
.jpeg)
When selecting an AI voice generator, it's crucial to evaluate factors such as functionality, ease of use, cost-effectiveness, and customer support. Users should seek a platform that aligns with their project requirements and budget constraints. The AI voice generator market is dynamic, with frequent technological advancements and feature updates. Staying informed about the latest developments is key to making the best choice for your voice synthesis needs. Regular research and staying abreast of industry changes will ensure that users have access to the most current and capable tools available.